

At Mobnia we pride ourselves in building digital products that help you succeed. But how do you build a software product that is reliable and robust? This is the sixth in a series of posts that address this question.
Low-level design fills in the gaps from high-level design to provide the extra detail necessary for developers to write code. It provides more specific guidance for how parts of the system will work and how they'll work together. It focuses on the how rather than the what.
There are important concepts that should be considered at this stage. They explain how to refine an object model to identify the app's classes, how to use stepwise refinement to provide additional detail for a task and how to design a flexible and robust database.
OO Design
Major types of classes for the app are defined in the high-level design. The specific classes (with definitions of their properties, methods, etc) are identified here in the low-level design.
Identifying Classes
One way to do this is to look for nouns in a description of the app's features. While doing this, you should think about what sort of information the class needs (properties), what sort of things it needs to do (methods) and whether it needs to notify the program of changing circumstances (events).
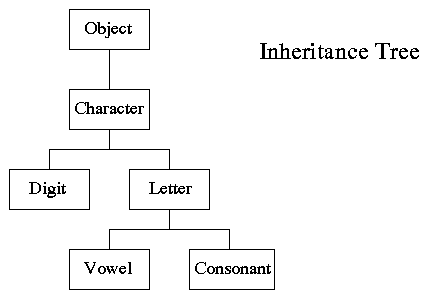
Building Inheritance Hierarchies
After defining the main classes, you need more detail to represent variations on the classes. Your application may, for example, require a User class, but users have different privileges. To capture these differences, you can derive a child class from a parent class.
Child classes inherit the properties, methods, and events (collectively called members) defined by their parent classes. So they can use code from said parent classes without you needing to rewrite it.
Conversely, child classes are treated in the same way the program treats their parent class. The app could create a data structure of Page objects and fill it with Page's child classes without knowing their true classes. This ability to treat objects as if they're from a different class is called polymorphism.
Most languages don't allow more than one parent for a class (multiple inheritance). Based on this, a class can, therefore, have at most a single parent class and any number of child classes. These relationships form a tree-like inheritance hierarchy.
You can modify these relationships in a lot of ways. You could add members unavailable to a parent class to its child class, or a child class could replace its parent class member with a new version. The details of how you do all these depend on the language you use, but here are the main two ways of building inheritance hierarchies.
Refinement
This is the process of breaking a parent class into multiple sub-classes to capture differences between objects in the class. You could break a Page class into Article and Gallery sub-classes. You can, however, over-refine when you unnecessarily refine the hierarchy.
You should focus on * behavioral* differences between the objects rather than the differences in their properties. If you have a Car class with sub-classes Mustang and Picanto. Although the Mustang accelerates quicker, both cars can accelerate (they just do so at different rates). You can, therefore, represent this difference with an Acceleration property instead of creating classes.
 Photo by Joey Banks on Unsplash
Photo by Joey Banks on Unsplash
If, on the other hand, the difference between them were the transmission type. To accelerate on both cars, you would go through different steps as the Mustang uses a manual transmission while the Picanto has an automatic transmission. This is a behavioral difference. Both cars can accelerate, but they go about it in different ways. In object-oriented terms, the Car class would have Automatic and Manual sub-classes that implement an Accelerate method differently.
Generalization
This does the opposite of refinement. It starts with several classes and creates a parent for them to represent common features. Re-using the example from above, you want to move the cars your application controls, so you call the Accelerate method in your Car parent class. Said method is defined by the parent class, but the child classes provide their own implementations. You can do this because the subclasses share features so you can create a parent class to define them.
You should be careful not to go overboard and create unusable parent classes. You could have an application for managing a zoo and decide to create an LivingThings parent class for Visitors and Animals (they're all living things, right?). Unfortunately, there's probably never going to be a time when the application would need to perform the same operation on animals and visitors in the zoo, so they shouldn't be merged into one hierarchy.
Hierarchy warning signs
There are some questions you should ask yourself when trying to decide if you have an effective hierarchy.
-
Is it tall and thin? These generally are more confusing than shorter ones. It's difficult to remember what class to use under different circumstances if the tree is tall. You should keep it under five levels unless you absolutely need to go higher.
-
Do you have a humongous number of classes? Sometimes
somemany of these classes can be replaced with simple properties. -
Does a class have just a single subclass? If this is the case, you probably can remove it and move its functionality into the subclass.
-
Is there a class at the bottom of the hierarchy that is never instantiated? There is? You don't need it then.
-
Do all the classes make common sense? There's probably something wrong if your
Userhierarchy contains aGalleryclass. -
Do classes represent differences in a property's value rather than in behavior or the presence of properties?
Object Composition
There are other ways to reuse code asides from inheritance. One of these is object composition, a technique that uses existing classes to build more complex classes.
Suppose you had a Smartphone class with IMEINumber, Model and Dimensions properties. Then you had a Dock class that should include information about compatible smartphones.
Making the Dock class inherit the Smartphone class (hence inheriting its properties) wouldn't make intuitive sense. A dock isn't a type of smartphone. Instead, give the Dock class a new property of type CompatibleSmartphone. This saves you the problems that could arise from an illogical inheritance. It also allows you to store multiple CompatibleSmartphones.
Database Design
There are lots different kinds of databases that you can use in an application. The most popular are relational databases. They're easy to use and provide good tools for database operations. They're also what will be used in this section. This is not, however, an extensive or in-depth coverage of relational databases.
Relational Databases
These store data in tables, with each table holding records containing related data. The data in each record are called fields. Each field has a name and a data type. All the values in the records containing that particular field have the same data type.
Relationships can be defined between the database tables. A CustomerId field may appear in the Customers and Orders tables in a database and hence, form a relationship between them. To find a customer's order, you would look up their id in the Customers table, and then find the corresponding id in the Orders table.
A useful relationship is the foreign key relationship. A foreign key is a set of one or more fields in one table with values that uniquely define a record in another table. The CustomerId field in the previous example is a foreign key in the Order (also known as the child table) table. It uniquely identifies records in the Customer (also known as the parent table) table.
If you don't design your table properly, you could encounter unexpected anomalies like:
- duplicate data that wastes space and makes updating values slow.
- the inability to delete one piece of data without deleting another unrelated piece of data.
- unnecessary pieces of data that may need to exist so you can represent some other data.
- a database that may not allow multiple values when you need them.
Database normalization is the process of rearranging a database to put it into a standard form that prevents these anomalies. There are seven levels of normalization, but the first three handle the worst kinds of problems.
First Normal Form
1NF as it is typically written, says the table can meaningfully be placed in a relational database. Most database products enforce the 1NF rules automatically so your database will be in 1NF with little extra work. The official rules are:
-
Each column must have a unique name.
-
The order of rows and columns doesn't matter.
-
Each column must have a single data type.
-
No two rows can contain identical values.
-
Each column must contain a single value.
-
Columns can't contain repeating groups.
You can find out more about the 1NF here.
Second Normal Form
For a table to be in 2NF (you should be getting the hang of this by now), it needs to satisfy the following rules:
- It's in 1NF
- All non-key fields depend on all key fields
A key is a set of one or more fields that uniquely identifies a record. For a table, being in 1NF implies having a key because of its rule 4 (no two rows can contain identical values).
You can find some examples of conversion to 2NF here and here.
Third Normal Form
A table is in 3NF if:
- It's in 2NF
- It contains no transitive dependencies
A transitive dependency is when a non-key field's value depends on another non-key field's value.
You can find out more about transitive dependencies and the 3NF here and here.
Higher levels of Normalization
These include the Boyce-Codd normal form (BCNF), the fourth normal form (4NF), the fifth normal form (5NF) and the Domain/Key normal form (DKNF). Some of these are rather technical and are better covered in dedicated database design books. Most designs stop at 3NF because it handles most anomalies without a huge amount of effort. Higher levels may also introduce confusion into the design, making it harder to use and less intuitive.